
Map Reduce
Mis à jour :
MapReduce is:
- A simple programming model for processing huge data sets in a distributed way.
- A framework that runs these programs on clusters of commodity servers, automatically handling the details of distributed computing :
- Division of labor.
- Distribution.
- Synchronization.
- Fault-tolerance.
Hadoop is one of the famous implementation of the MapReduce programming model and execution framework
How does it work?
MapReduce is a programming model and an associated implementation for processing and generating large data sets. Speficically:
- Map function that processes a key/value pair to generate a set of intermediate key/value pairs.
- Reduce function that merges all intermediate values associated with the same intermediate key.
Many real world tasks are expressible in this model, as shown in the paper.
Programs written in this functional style are automatically parallelized and executed on a large cluster of commodity machines. The run-time system takes care of the details of partitioning the input data, scheduling the program’s execution across a set of machines, handling machine failures, and managing the required inter-machine communication. This allows programmers without any experience with parallel and distributed systems to easily utilize the resources of a large distributed systems.
The basic principle is:
- Divide a task into independent subtasks
- MAP: Handle the sub-tasks in parallel
- REDUCE: Aggregate the results of the subtasks to form the final output
MapReduce in details
Clustered File System vs. Distributed File System
Before discussing Map Reduce inner workings, we should first get an idea of how it is informatically supported. There are two ways of letting worker access the data:
Send the workers to the data or send the worker to the data.
Definition: (Clustered File Sytem) A shared-disk file system. The most common type of CFS, uses a storage-area network (SAN) to allow multiple computers to gain direct disk access at the block level. This is further extracted by your database management system (DBMS).
Definition: (Distributed File Systems) Send data to each clusters.
Master / Worker
The first step in creating a parallel program is to identify a set of tasks and/or partitions of data that can be run concurrently.
This is usually done with the following in mind:
- The Master
- Initialize arrays and splits them according to available workers
- Sends each worker their subarray
- Receives the response from each worker
- The Worker
- Receives the subarray from the master
- Performs processing on the subarray
- Returns the results to master
Load balancing
Load balancing refers to techniques that spread tasks among the processors in a parallel system to avoid some workers getting repeatedly queued while others are idle. To stir up some imagery think of it as the ideal implementation of communism.
While static balancers allow for less overhead they take no account of the current network load.
In the inverse, dynamic balancers offer a more flexible, but more computationally expensive, allocation while giving thought to the network.
Complete scheme of MapReduce
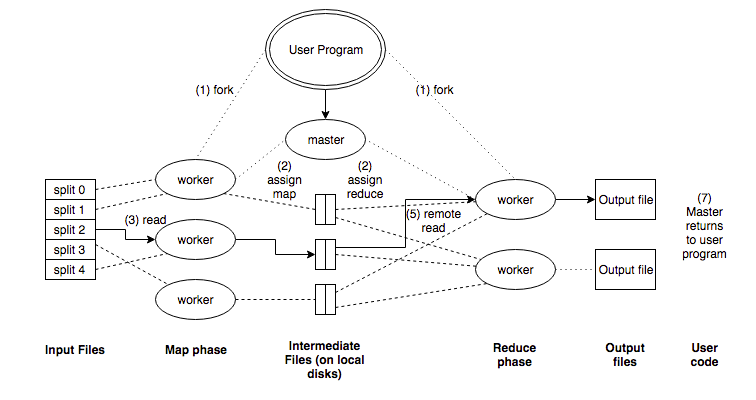
- The MapReduce library in the user program first shards the input files into M pieces of typically 16MB-64MB/piece. It then starts up many copies of the program on a cluster of machines.
- One of the the copies of the program is special: the master. The rest are workers that are assigned work by the master. There are M map tasks and R reduce tasks to assign. The master picks idle workers and assigns each one either an M or R task.
- A worker who is assigned a map task reads the content of the corresponding input shard. It parses key/value pairs out of the input data and passes each pair to the users-defined Map function. The intermediate K/V pairs produced are buffered in memory.
- Periodically, the buffered pairs are written to local disk, partitioned into R regions by the partitioning function. The locations of these buffered pairs on the local disk are passed back to master, who is responsible for forwarding these locations to the reduce workers.
- When a reduce worker gets the location from master, it uses remote calls to read the buffered data from the disks. When a reduce worker has read all intermediate data, it sorts it by the intermediate keys so all of the same occurrences are grouped together. (note: if the amount of intermediate data is too large to fit in memory, an external sort is used)
- The reduce worker iterates over the sorted intermediate data and for each unique intermediate key encountered, it passes the key and corresponding set of intermediate values to the user’s Reduce function.
- The output of the Reduce function is appended to a final output file for this reduce partition.
- When all map tasks and reduce tasks have been completed, the master wakes up the user program. At this point, the MapReduce call in the user program returns back to the user code.
Execution notes:
- After successful completion, the output of the MapReduce execution is available in the R output files.
- To detect failure, the master pings every worker periodically. If no worker response after a certain point, the worker is marked a “failed” and all previous task work by that worker is reset, to become eligible for rescheduling on other workers.
- Completed map tasks are re-executed when failure occurs because their output is stored on the local disk(s) of the failed machine and therefore inaccessible. Completed reduce tasks do not need to be re-executed since their output is stored in a global file system.
Exemple: word counting
We want to count the occurences of each word in a lot of different files. Specifically, for several text files, we will design the mapper and reducer, prior to run on Hadoop two clusters that count the words of the text files.
Step 1: Create the mapper and the reducer
Mapper
#!/usr/bin/python
"""
Mapper part of the word counting problem.
The first line of this code mus be written to work with the virtual box.
"""
import sys
for line in sys.stdin:
line = line.strip()
keys = line.split()
for key in keys:
value = 1
print("{0}\t{1}".format(key, value))
Reducer
#!/usr/bin/python
"""
Reducer part of the word counting problem.
The first line of this code mus be written to work with the virtual box.
"""
import sys
# Initialize these variables
last_key = None
this_key = None
running_total = 0
# Iterate through standard input file line by line
for input_line in sys.stdin:
"""
Key: corresponds to the word we are counting
Value: corresponds to its current value
"""
# Remove spaces, indents... at the beginning/end of the line
input_line = lien.strip()
# Break input_line with the separator \t (tab indent)
this_key, value = input_line.split("\t", max_split = 1)
value = int(value) # Make sure we count integers!
# Add the value to the key if it remains unchanged
if last_key == this_key:
running_total += value
print("{0}\t{1}".format(last_key, running_total))
# Reinitialize running_total and change last_key
else:
running_total = value
last_key = this_key
Step 2: Make it executable
We need to specify an executable file to the mapper / reducer. This is because each mapper task will launch the executable as a separate process. This why we add “writing rights” with the folloing line of code:
chmod +x /home/cloudera/WordCount/Python/mapper_wordcounting.py
Step 3: Create HDFS input directory
- To create a directory for the HDFS files:
hdfs dfs -mkdir Directory. If the directory exists and you wish to recreate it (Careful):hdfs dfs -rm -r /user/cloudera/input_wordcounthdfs dfs -mkdir /user/cloudera/input_wordcount
- Put the files in it:
hdfs dfs -put /home/cloudera/Files/testfile* /user/cloudera/input - Check there is everything you need:
hdfs dfs -ls /user/cloudera/input - Check its health:
hdfs fsck /user/cloudera/input
Step 4: Run hadoop map-reduce
Finally, we launch hadoop:
hadoop jar/usr/lib/hadoop-mapreduce/hadoop-streaming.jar\
-input /user/cloudera/input\
-output/user/cloudera/output\
-mapper /home/cloudera/wordcount_mapper.py\
-reducer /home/cloudera/mapper_wordcouting.py
Laisser un commentaire