
Word embeddings
Mis à jour :
An embeddings is a representation of an object (word, image) formulated as continuous vectors. They are constructed so that similar objects can have similar embeddings (metric learning). Usually, embeddings are not the final goal but are rather used as features (feature learning).

Most recently, embeddings have been learned with neural networks. However, they are not the end result of the network but the final (trained) parameters of the last layer of the encoder.
Example: Convnet encoder
- Train your ConvNet on a large supervised image-classification task (ImageNet)
- Encode your image with the ConvNet with the hidden layer between convolutional neural network and fully connected network.
Usefullness:
- We can compute the learned similarity distance to find similar images.
- The learned features can be injected into another model
This neural network has to be trained to solve a particular task, but which one? This is detiled in the next paragraph:
Word2vec: unsupervised word embeddings
Word2vec is a fast C++ tool to obtain word embeddings from an unsupervised corpus of text. It consists of two models:
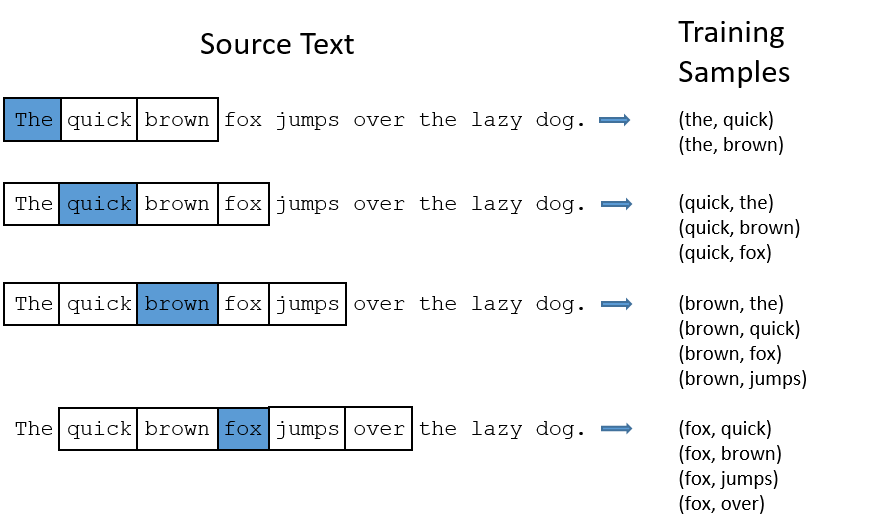
- SkipGram which predict the surrounding words from the center word
- CBOW: predict center word from surrounding words
SkipGram
Word2vec goes through a text corpus sequentially. When it encounters a given word $w$, it constructs a list of the pairs $(w, v)$ of each surrounding word $v$ (within a pre-defined window).
CBOW
Once we have pairs of close words, our goal becomes to be able to predict that “love” should be close to “feeling”.
This prediction is supported by a neural network with:
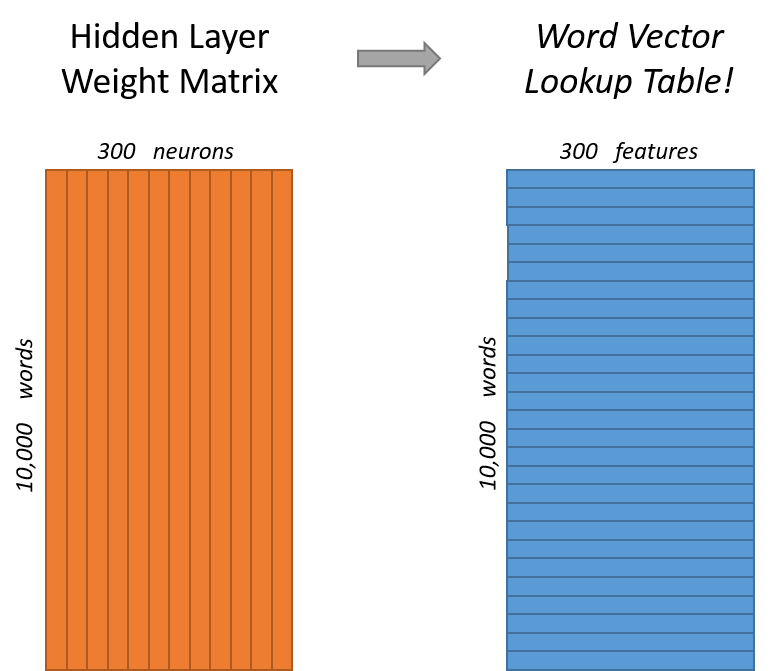
- Input: Create vocabulary (one-hot encoder vector of a set of words). For the words “cat”, “dog”, “human”: “dog” is represented as [0, 1, 0]. Typically, they have around 10k word.
- Hidden layer: This is what we want, as the weights of this layer are the embeddings. It should have less neurons than words in our vocabulary ($\approx 300$)
- Output: For each word $w$ construct a probability vector for every other words $v$ within the list of pairs generated by SkipGram.
We train this neural network with cross-entropy loss and SGD.
Ultimately, it produces a « lookup table » which transforms « love » into a word vector (i.e. its embedding).
Note: It is possible to encode bigrams (“irish setter”) with word2vec.
Optimizing the softmax
For large vocabulary $V$ the softmax is expensive. There are two solutions to fight this: Negative sampling or Hierarchical softmax.
Negative sampling objective is composed of two terms:
- Attractive force: reduce the distance between a word and one of its neighbors
- Repulsive force: increase the distance between a word and a random word
Note: word2vec can encode unigrams and bigrams
Word similarity and analogy
Once these vectors are obtained with the above model, we can perform typical vector operations: (addition, angles)
- Word similarity
- Word analogy:
Code
Usually it boils down to download already trained word2vec. If you wish to build a custom and robust word2vec, you can go to here. In plain python, we can build one by:
Import the basics
import io
import os
import numpy as np
path_data = "data/"
class Word2vec():
"""
Rudimental implementation of Word2Vec. This class can read a pre-trained *.vec and
perform cosine similarity and k-most similar. It deals with external words
missing from the pre-trained model.
"""
def __init__(self, fname, max_words=100000):
self.load_wordvec(fname, max_words)
self.embeddings = np.array(self.word2vec.values())
def load_wordvec(self, fname, max_words):
self.word2vec = {}
with io.open(fname, encoding='utf-8') as f:
next(f)
for i, line in enumerate(f):
word, vec = line.split(' ', 1)
self.word2vec[word] = np.fromstring(vec, sep=' ')
if i == (max_words - 1):
break
print('Loaded %s pretrained word vectors' % (len(self.word2vec)))
def most_similar(self, w, K = 5):
# Cosine similarity for every words.
similarities = {k : self.cosine_similarity(w, k) for k, v in self.word2vec.items()}
# Return the k-th element of the sorted dictionary
return(sorted(similarities, key=similarities.get, reverse=True)[-K:])
def cosine_similarity(self, u, v):
# Compute the dot product of each word and normalize
dot_product = np.dot(self.word2vec[u], self.word2vec[v])
normalizer = np.linalg.norm(self.word2vec[u]) * np.linalg.norm(self.word2vec[v])
return dot_product/float(normalizer)
def assign_w2v(self, word):
# Deal with external word not present.
try:
return(self.word2vec[word])
except KeyError:
return(None)
# Instanciate Word2vec with our data and the max nb of words
w2v = Word2vec(os.path.join(path_data, 'crawl-300d-200k.vec'), max_words = 200000)
# Similarity scoring
for u, v in zip(('cat', 'dog', 'dogs', 'Paris', 'Germany'), ('dog', 'pet', 'cats', 'France', 'Berlin')):
print(u, v, w2v.cosine_similarity(u, v))
# Most similar words
for u in ['cat', 'dog', 'dogs', 'Paris', 'Germany']:
print(w2v.most_similar(u))
Variants and extensions of word2vec
« FastText »
FastText adds character-level information by setting word embeddings as the sums of char-n-gram embeddings:
- $w_{love} = w_{lov} + w_{ove}$
- $w_{loving} = w_{lov} + w_{ovi} + w_{vin} + w_{ing}$
Multilingual word embeddings
Aligning monolingual word embedding spaces by creating a linear mapper $W$ between the languages $X$ and $Y$.
It works by minimizing the reconstruction error between $Y$ and $WX$. Specifically the following objective is miminimzed:
Sources and additional reading:
- Blog post by Chris McCormick
Mikolov et al. (2013) – Exploiting Similarities among Languages for Machine Translation for more details.
Laisser un commentaire