
MXNet in a nuthsell
Mis à jour :
As per MXNet documentation:
While GPUs and clusters present a huge opportunity for accelerating neural network training, adapting traditional machine learning code to take advantage of these resources can be challenging. The familiar scientific computing stacks (Matlab, R, or NumPy & SciPy) give no straight-forward way to exploit these distributed resources.
-> There is no consensus on how one should leverage GPU and cloud computing to do Machine Learning.
Acceleration libraries like MXNet offer powerful tools to help developers exploit the full capabilities of GPUs and cloud computing. While these tools are generally useful and applicable to any mathematical computation, MXNet places a special . In particular, we offer the following capabilities:
-> MXNet emphasis on speeding up the development and deployment of large-scale deep neural networks
- Device Placement: With MXNet, it’s easy to specify where each data structures should live.
- Multi-GPU training: MXNet makes it easy to scale computation with number of available GPUs.
- Automatic differentiation: MXNet automates the derivative calculations that once bogged down neural network research.
- Optimized Predefined Layers: While you can code up your own layers in MXNet, the predefined layers are optimized for speed, outperforming competing libraries.
1. Deep Nets on Fast Computers
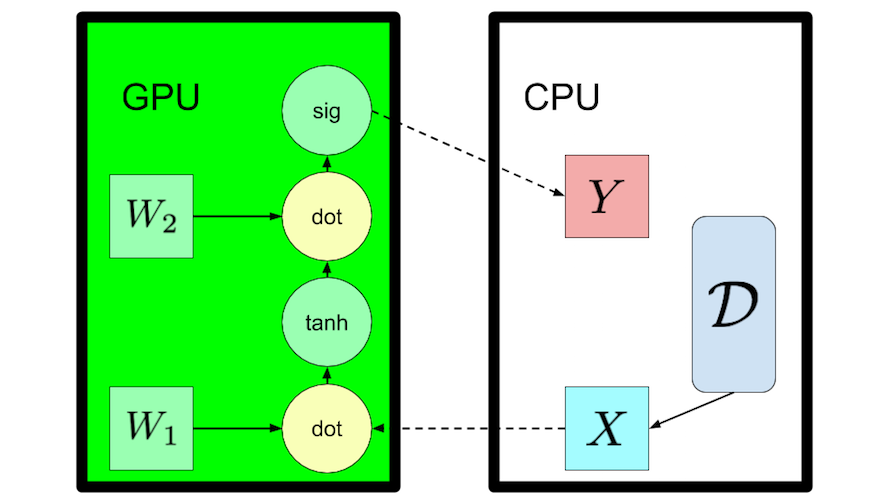
In a nutshell, all Neural Networks map an input X to an output Y with layers of computation, with each layer being a linear function paired with a non-linear transformation:
hidden_linear = mx.sym.dot(X, W)
hidden_activation = mx.sym.tanh(hidden_linear)
where W are the weights to learn. The problem is to perform these operations efficiently with a simple interface. This is where MXNet comes in:
- MXNet provides optimized numerical computation for GPUs and distributed ecosystems, from the comfort of high-level environments like Python and R
- MXNet automates common workflows, so standard neural networks can be expressed concisely in just a few lines of code
2. Nuts and Bolts
Imperative Programming with NDArray¶ Symbolic Programming in MXNet¶
Building Models with MXNet Layers¶
Conclusions Given its combination of high performance, clean code, access to a high-level API, and low-level control, MXNet stands out as a unique choice among deep learning frameworks.
Laisser un commentaire